
こんにちわ、PHPエンジニアのエンジニア婦人(@naho_osada)です。
PHPエンジニアとして9年~の経験があります。
少し前にnodejsのpuppeteerを使って、Webページのキャプチャを撮って、pdfmakeを使っていい感じのPDFに仕上げる、という仕事をしました。
これが中々面白くて、「自分のサイトのレシピ情報をpuppeteerで取得してPDFで保存できないかな?」と思い、作ってみました。
「puppeteer / jimp / pdfmakeでレシピPDFを作ってみた」記事一覧
- 【nodejs】puppeteer / jimp / pdfmakeでレシピPDFを作ってみた-自動でスクリーンショット編-
- 【nodejs】puppeteer / jimp / pdfmakeでレシピPDFを作ってみた-jimpで画像分割、Promise編-
- 【nodejs】puppeteer / jimp / pdfmakeでレシピPDFを作ってみた-PDF生成と後処理編-
プログラムの流れ
やりたいことは「自分のサイトのレシピ情報をpuppeteerで取得してPDFで保存」です。
- 一覧ページからキャプチャ対象となるページのURLを全部取得
- ページのURLに一つずつアクセスして、該当部分をキャプチャして保存
- 保存した画像をPDF1ページの幅に合う大きさにリサイズ
- リサイズした画像をPDF1ページの高さに合うように分割保存
- PDF出力(画像を1ページずつ貼り付けていく)
- 使用した画像を削除
となります。
ここでは1~3番を説明します。
出力されるPDFのサンプルです(20ページほど、少々重たいかもしれません)。
備考
ここでは「キャプチャを貼り付けてPDF化」の方法を取ります。
そのため、「改ページの際に画像や文字が切れる部分がある」と思われますが、今回はその部分の調整は一切しません。
要は「ウェブページを見たまま保存する」ということになります。ブラウザ上で「このページを印刷する」とやったときに近い(けど遠い)です。
もし切れる部分が嫌であれば、本文を文字列として取得、画像部分のみをキャプチャし、その配置を調整しながらpdfmakeで出力することになります。
見た目はウェブページの通りにまずなりませんし、画像の挿入部分の調整など、想像しただけで地獄です。自動化にも向かないかもしれません。ただ、やればできるとは思います。
各処理の考え方
1. 一覧ページからキャプチャ対象となるページのURLを全部取得
カテゴリー一覧ページにある、「主菜」「副菜」「汁物」「デザート」を対象とします。
これらページに表示される、各カテゴリの記事のURLを取得します。

puppeteerでカテゴリー一覧ページにアクセスし、これらのカードのURLを集めます(URLは配列に保存します)。
※2020年10月時点では対象カテゴリ内で次のページが存在しないため、次のページのクリック、及び更に取得するプログラムは実装していません。
※次のページがある場合、リンクを取得してクリックしてURLを収集してくる…という流れにするとよりpuppeteerらしいですね。
該当ソース
// ▼ puppeteer ▼
const browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox'],
});
const page = await browser.newPage();
await page.setViewport({width: 1500, height: 10000});
// タイムアウトなし
page.setDefaultTimeout(0);
// キャプチャの保存先ディレクトリの生成確認
makeDir(capPath);
// ▼ キャプチャを取得するURLをまとめる ▼
var targetUrl = new Array();
for(var i in UrlList) {
await page.goto(Url + UrlList[i], {waitUntil: ["load", "networkidle2"]});
// 指定の部分を取得
await page.waitFor(target)
// リンクを取得する
var datas = await page.$$eval(targetDom, hrefs => hrefs.map((a) => {
return a.href;
}));
for(var i2 in datas) {
targetUrl.push(datas[i2]);
}
}
// ▲ キャプチャを取得するURLをまとめる ▲
2.ページのURLに一つずつアクセスして、該当部分をキャプチャして保存
集めた各ページのURLに一つずつアクセスしていきます。
アクセスしたページの本文領域のみを指定してキャプチャ、保存します。
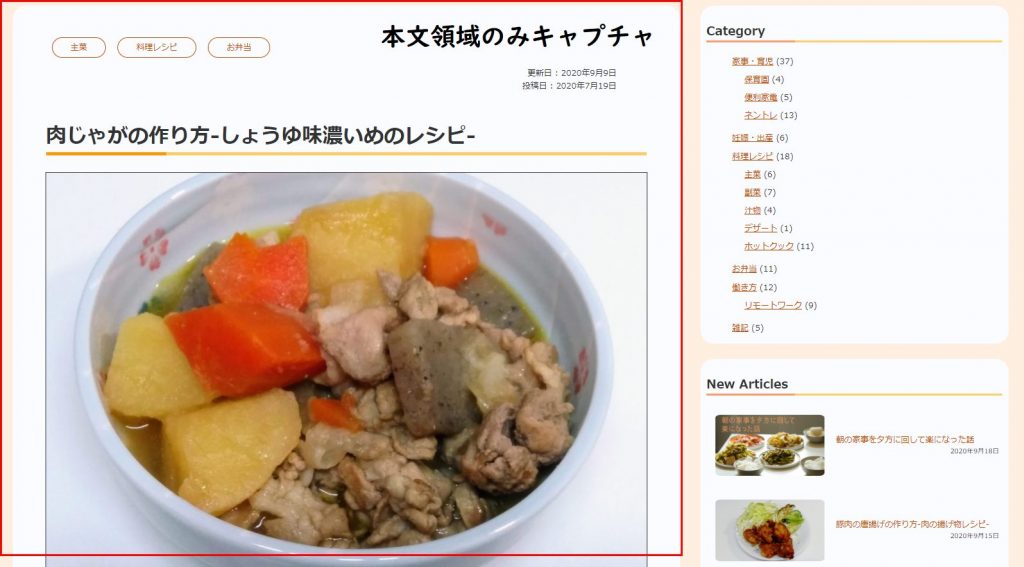
該当ソース
var cnt = 1;
var capFile = '';
for(var i in targetUrl) {
await page.goto(targetUrl[i], {waitUntil: ["load", "networkidle2"]});
// 指定の部分を取得
await page.waitFor(capArea);
const clip = await page.evaluate(s => {
const el = document.querySelector(s)
// エレメントの高さと位置を取得
const { width, height, top: y, left: x } = el.getBoundingClientRect()
return { width, height, x, y }
}, capId);
capFile = capPath + cnt + '.png';
await page.screenshot({clip, path: capFile});
cnt++;
}
3.保存した画像をPDF1ページの幅に合う大きさにリサイズ
キャプチャ保存をしたあと、「PDFの幅」でリサイズしておきます。
PDFに貼り付けたときに横幅が見切れないのは500程度のようです。
該当ソース
// 取得したキャプチャをリサイズする
await jimp.read(capFile).then((data) => {
data.resize(width, jimp.AUTO).write(capFile);
}).catch((err) => {
console.log(err)
});初めからpuppeteerで幅500でキャプチャすればいい?
puppeteerのウィンドウサイズを小さくしてキャプチャすれば、本文領域が500程度で取得できます。
しかしそれをやると、本文の文字が大きくなってしまい、PDFにしたときに見辛くなります。
puppeteerでウィンドウサイズがある程度大きい状態でキャプチャし、その後リサイズをすると、文字が大きすぎる問題を防ぐことができます。
今回のプログラム全文
今回使用したプログラムの全文です(※本件の動作部分なので、GitHubにある物とは異なります)
const puppeteer = require('puppeteer');
const jimp = require('jimp');
const fs = require('fs');
const { exit } = require('process');
// 取得したキャプチャとそれを分割した画像の保存先パス
const capPath = './captcha/';
const cropPath = './crop/';
// PDFのファイル名
const pdfFile = './sample.pdf';
// ▼ 取得するURLの設定 ▼
const Url = 'URLを指定';
// 複数URLがある場合(Url以降が異なるものを複数取得する)
var UrlList = new Array();
UrlList.push('Url以下のPathを指定');
// ▲ 取得するURLの設定 ▲
// ▼ 取得するDOM要素の設定 ▼
// 環境によってそれぞれ異なります
const target = '.front-box';
// URLリストのターゲット
const targetDom = 'h3>a';
// キャプチャ取得するときに描画待機する場所(キャプチャする領域より下のタグやクラスを指定)
const capArea = '.bread-list';
// キャプチャするDOM要素やIDなど
const capId = 'article';
// ▲ 取得するDOM要素の設定 ▲
/**
* PuppeteerでターゲットのURLを取得し、ターゲットURLを訪問して指定部分のキャプチャを撮る
*/
(async() => {
try{
// ▼ puppeteer ▼
const browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox'],
});
const page = await browser.newPage();
await page.setViewport({width: 1500, height: 10000});
// タイムアウトなし
page.setDefaultTimeout(0);
// キャプチャの保存先ディレクトリの生成確認
makeDir(capPath);
// ▼ キャプチャを取得するURLをまとめる ▼
var targetUrl = new Array();
for(var i in UrlList) {
await page.goto(Url + UrlList[i], {waitUntil: ["load", "networkidle2"]});
// 指定の部分を取得
await page.waitFor(target)
// リンクを取得する
var datas = await page.$$eval(targetDom, hrefs => hrefs.map((a) => {
return a.href;
}));
for(var i2 in datas) {
targetUrl.push(datas[i2]);
}
}
// ▲ キャプチャを取得するURLをまとめる ▲
// ▼ 取得したURLを元にキャプチャを取得する ▼
var cnt = 1;
var capFile = '';
for(var i in targetUrl) {
await page.goto(targetUrl[i], {waitUntil: ["load", "networkidle2"]});
// 指定の部分を取得
await page.waitFor(capArea);
const clip = await page.evaluate(s => {
const el = document.querySelector(s)
// エレメントの高さと位置を取得
const { width, height, top: y, left: x } = el.getBoundingClientRect()
return { width, height, x, y }
}, capId);
capFile = capPath + cnt + '.png';
await page.screenshot({clip, path: capFile});
// 取得したキャプチャをリサイズする
await jimp.read(capFile).then((data) => {
data.resize(width, jimp.AUTO).write(capFile);
}).catch((err) => {
console.log(err)
});
cnt++;
}
// ▲ 取得したURLを元にキャプチャを取得する ▲
await browser.close();
resolve();
// ▲ puppeteer ▲
} catch(e) {
console.error('err' + e);
}
})();
/**
* makeDir
* 指定パスのディレクトリを生成する
* 既にディレクトリがある場合は何もしない
* 再帰的処理は行っていない(1階層のみ)
* @param path 生成パス
* @return true
*/
function makeDir(path) {
if(!fs.existsSync(path)) {
fs.mkdirSync(path);
}
return true;
}
まとめ
ウェブページの内容の欲しいところだけを、自動でキャプチャして保存するまでの処理を紹介しました。
nodejsで書いています。puppeteer、画像のリサイズ処理にjimpを使用しました。
次はjimpを使って、PDF1枚の高さに合うように画像を分割していきます。


