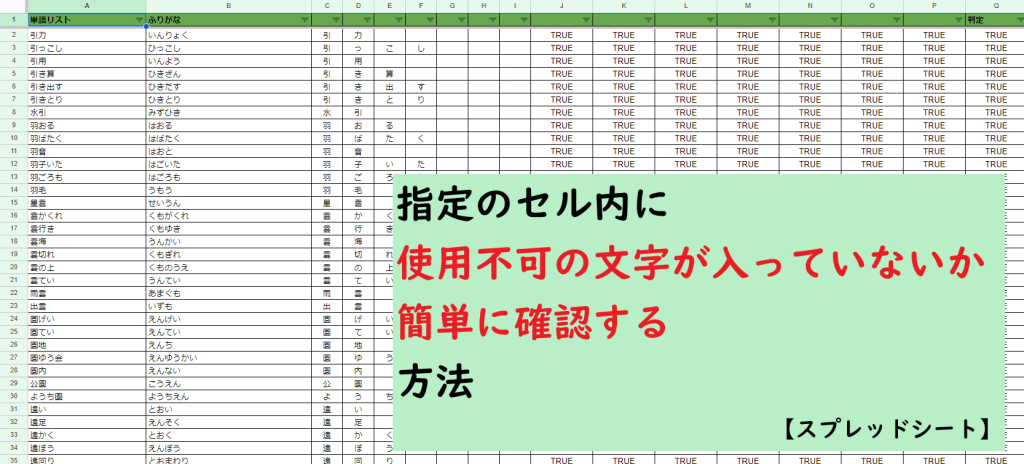
日々の業務で、例えば旧字体が入っているセルを見つけて修正したい、全角英数字が入っているセルを見つけて修正したいなど、特定の文字列が入っているセルを探し出す作業があるかもしれません。
ひとつひとつのセルを目視で見ていくのはすごく大変です。目視ゆえにミスも発生するかもしれません。それに探すのに時間をかけたくないしラクしたい…
以下の方法はそういったときの助けになるかもしれません。
ここでは指定外の文字列が入ったセルを探し出し、修正して確認する作業をスプレッドシート1つで行う方法を紹介しています。
今回はスプレッドシートで行いましたが、同じような関数があればエクセルでも適用できますよ。
事例:「ひらがな+カタカナ+指定の漢字以外が入ったセル」を探して修正する
先日、スタディチャレンジで小学2年生の漢字カードをリリースしました。
この漢字カードを作るにあたり、小学2年生までに習う漢字を使った単語リストを作成しています。
この単語リストを作成するときに、ひとつだけ注意することがあります。
「ひらがな」+「カタカナ」+「小学1~2年生で習った漢字」以外の文字列は外すことです。
小学2年生と言えば、まだ漢字を習っている最中。まだ習っていない漢字も多くあります。
小学2年生用に作るなら、「ひらがな」+「カタカナ」+「小学1~2年生で習った漢字」以外の文字列は外したいですよね。
この指定外の文字列が入ったセルを探し出し、修正して確認する作業をスプレッドシート1つでやっていきます。
以下、その手順を書いていきます。
1 小学2年生で習う漢字を使った単語リストを出す
まずは漢字カードに使うための漢字リストを作ります。
1年生80文字のときは辞書とにらめっこしながらリストを作りましたが、今回はChatGPTさんに協力を要請して160文字×100個=16,000個の漢字の単語リストを作成しました。
ChatGPTは途中まで手伝ってくれた(2024年1月時点)
リスト出しの際、ChatGPTに
以下のリストの漢字を使って単語を10個作ってください。人名、地名は使わないでください。(以下指定漢字10個)
などとお願いしてリスト出しをしてもらいました。
ただ「指定の漢字は必ず前にある」単語を出してくるのが難点です。「指定の漢字を後ろにしてください」としてもなかなかうまくいきませんでした。
そのため「指定の漢字が前にない単語」は自分で考えたり、辞書を見ながら作成しました。
また、「2年生までに習う漢字以外は使わないでね」のようなお願いも無視されてしまいました。リストを渡してもうまくいきませんでした。
今後の彼次第ではできるようになるかもしれませんね。
2 単語リストをスプレッドシートに貼る
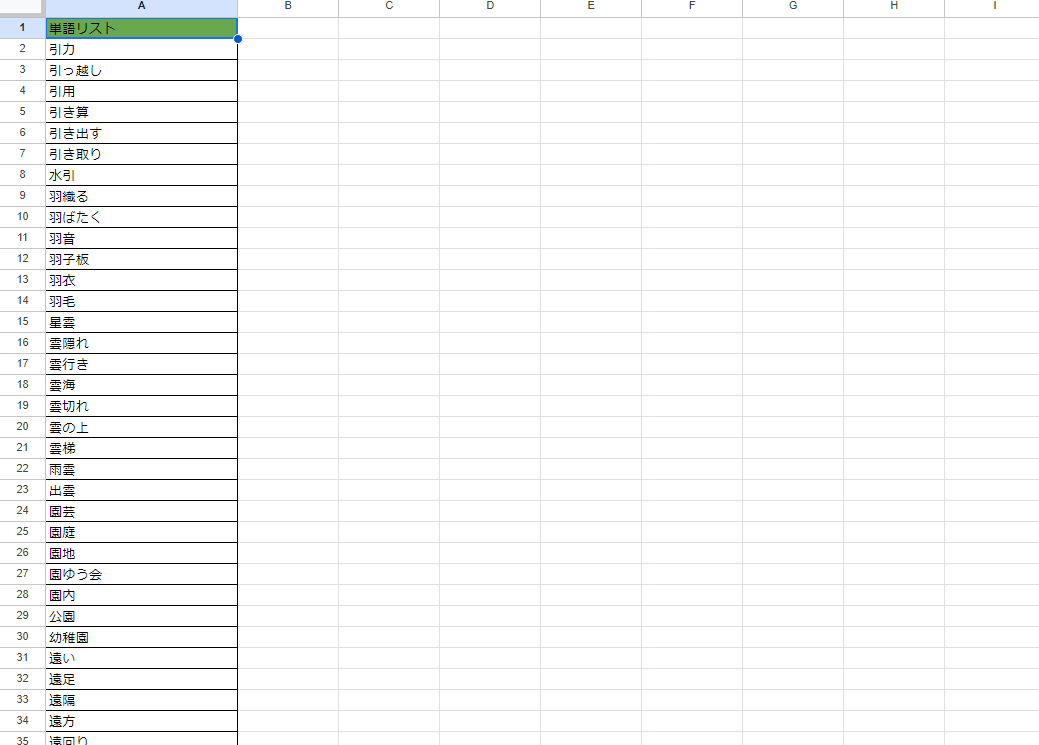
単語リストをスプレッドシートに貼り付けます(単語ごとに改行してあると、テキストエディタからそのまま貼り付けできますね)。
3 使用許可リストを作成する
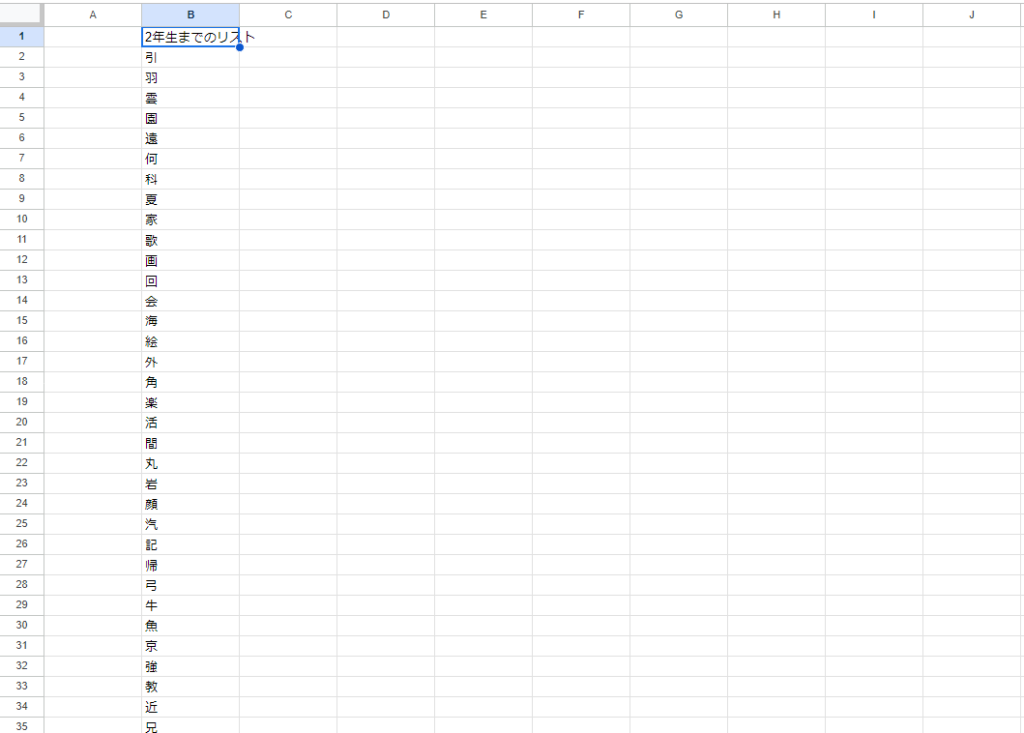
別のシートに、許容リストを作成します。
内容はひらがな+カタカナ+1年生で習う漢字80文字+2年生で習う漢字160文字です。
ひらがなとカタカナは濁音(「がぎぐげご」など)、半濁音(「ぱぴぷぺぽ」など)、拗音(小さい「ゃ」「ゅ」「ょ」など)もリストに入れます。
4 単語を1語ずつに分解する
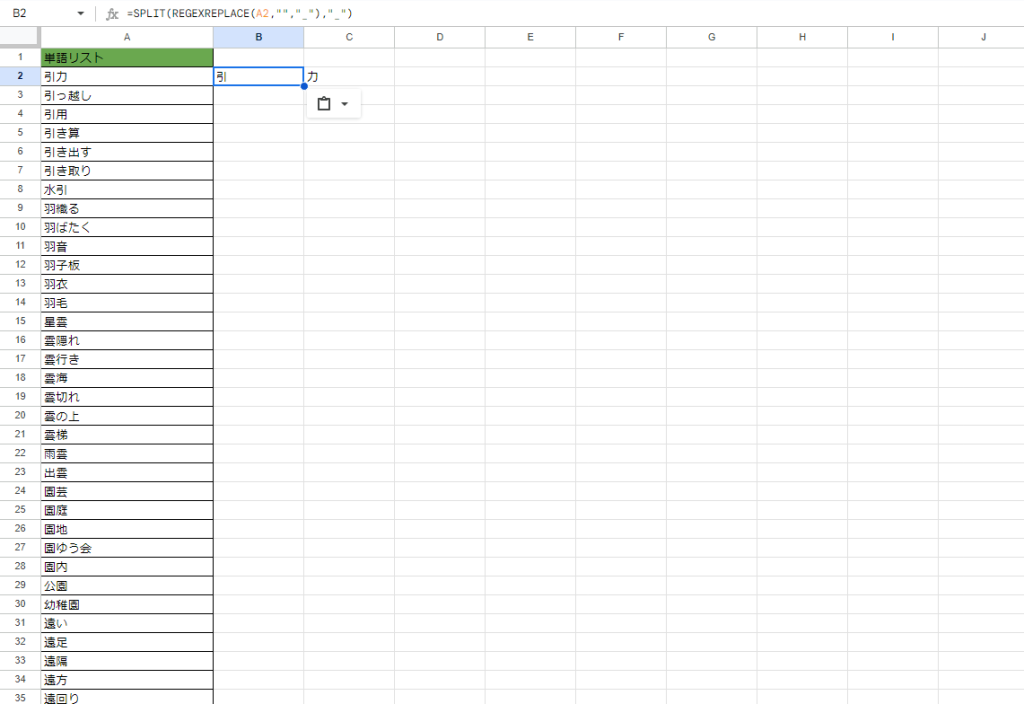
単語リストの文字を、1文字ずつに分解します。上の例でいうと
=SPLIT(REGEXREPLACE(A2,””,”_”),”_”)
になります。そうすると隣接セルに1文字ずつに分かれて表示されます。
リスト全部に適用すると以下のようになります。
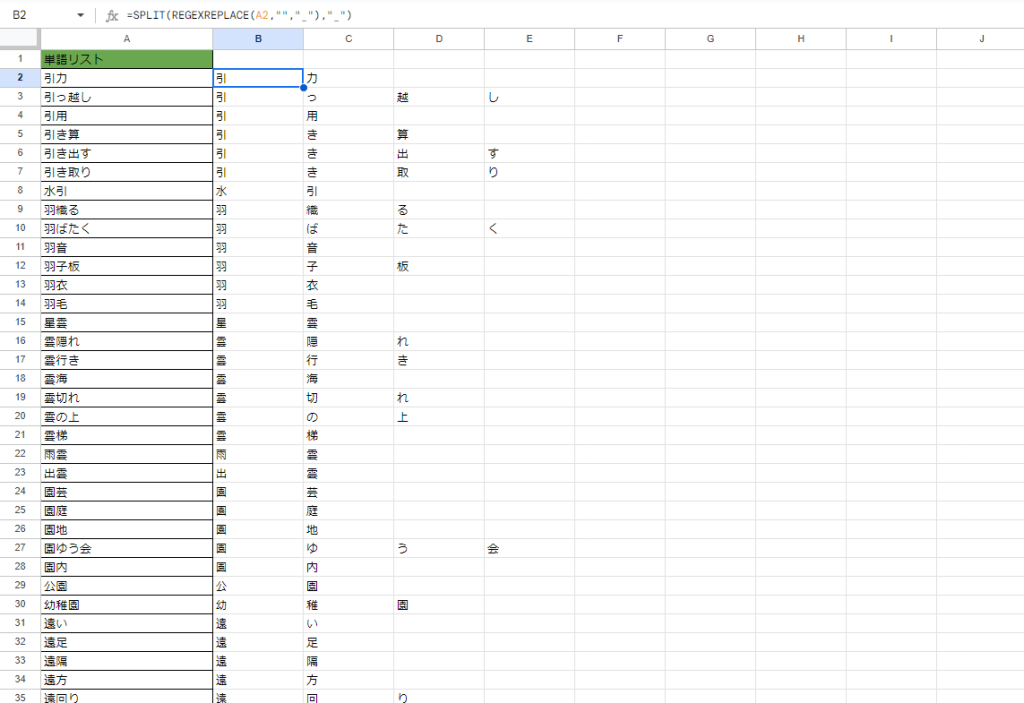
これで1文字ずつ、使える文字なのかどうなのか、判定する準備ができました。
補足:セルの中を指定するだけで全判定できれば一番ラクなのですが、それはちょっと難しいようでしたので「文字を1つずつ見て判断する」方法を取っています。。いい方法あるかな?
5 分解した文字列が使用可能なものか判定する
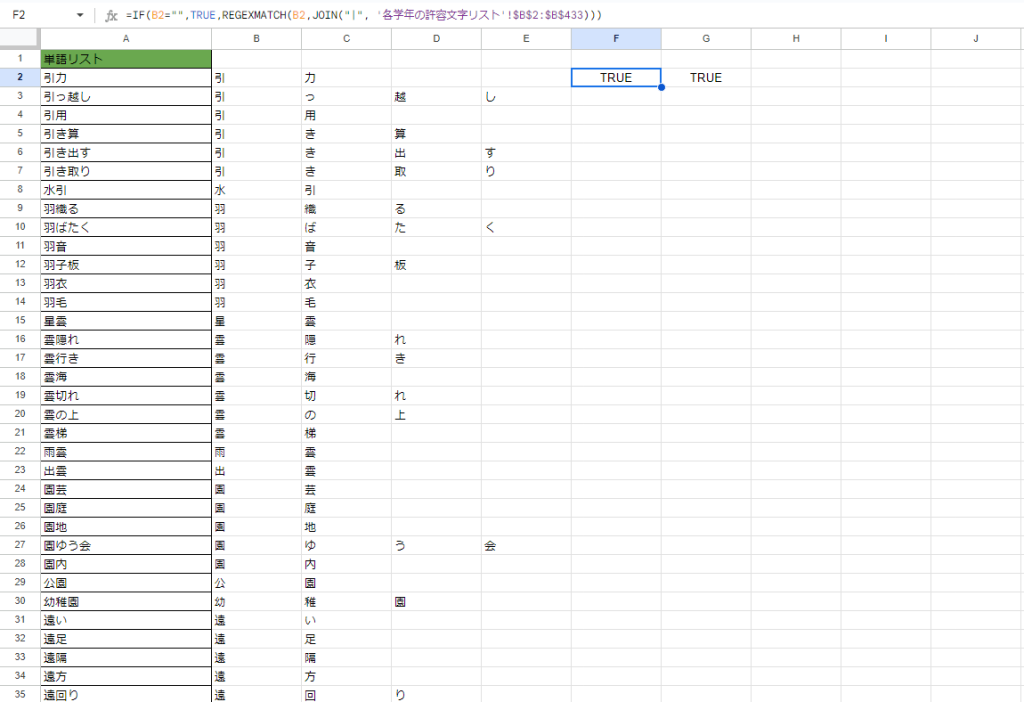
分解した後、1つずつ文字が使えるリストにあるかどうかを見ていきます。
=IF(B2=””,TRUE,REGEXMATCH(B2,JOIN(“|”, ‘各学年の許容文字リスト’!$B$2:$B$433)))
のようになっています。
日本語にすると、
もし空のセルだったらTRUE(真)を返すよ。
そうでなかったら各学年の許容文字リストにある中から含んでいるか判定するよ。
許容文字リストに含まれていたらTRUE(真)、含まれていなかったらFALSE(偽)を返すよ。
という意味になります。
「引力」の場合、どちらも許容リストに載っている文字なのでTRUEが2つ並びました。
これを全リストに適用すると、以下のようになります。
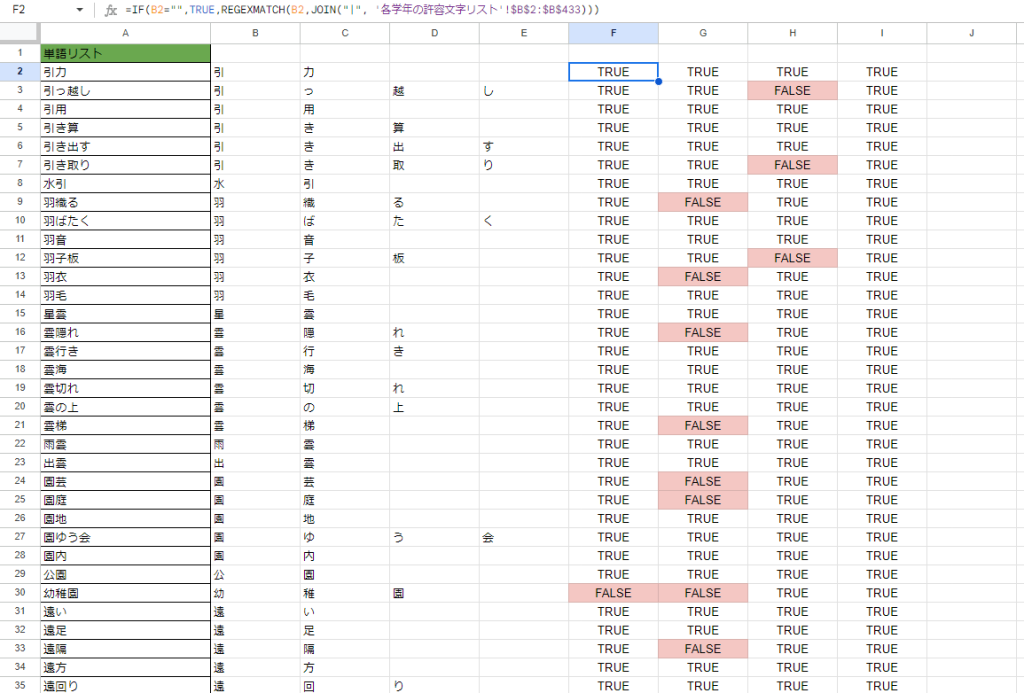
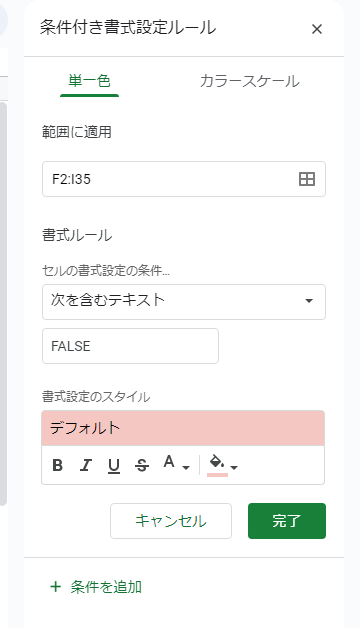
上記の表ではFALSEだった場合は目立つようにセルの色を変えるように、セルの条件付き書式設定で設定しています。
6 フィルタ用の真偽判定列を作る
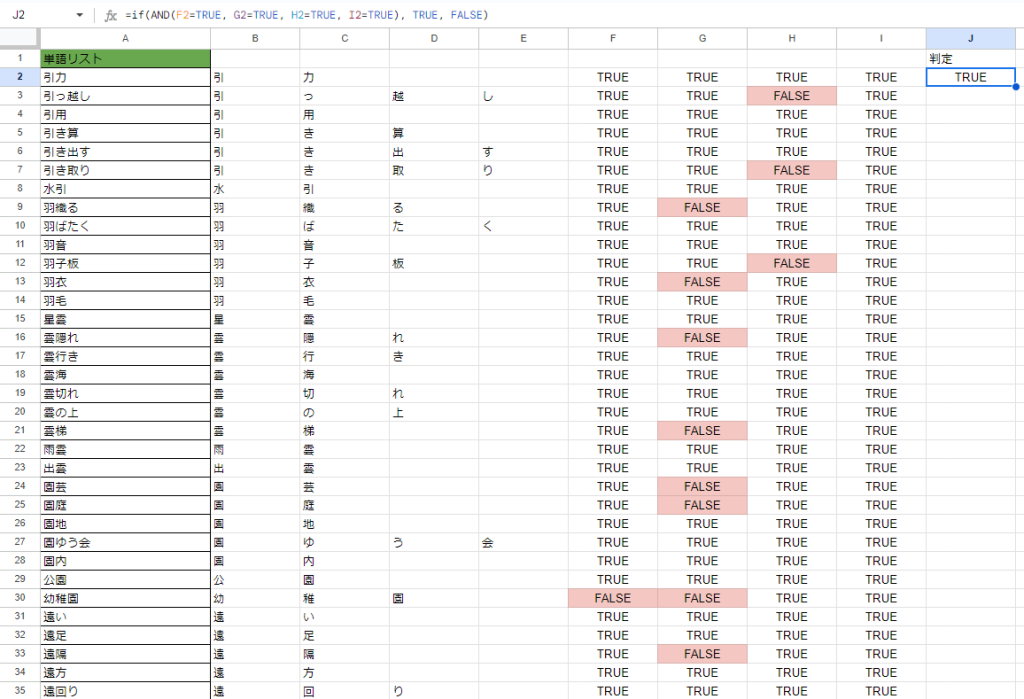
使用許可リストにない文字列を含むものはわかりましたが、これではどのセルが修正対象なのかわかりにくいですよね。
そこでFALSEがある単語行をリストアップできるように、フィルタ用の判定列を作ります。
=if(AND(F2=TRUE, G2=TRUE, H2=TRUE, I2=TRUE), TRUE, FALSE)
と書いてあります。真偽判定をしたセル行が全部TRUEであればTRUE、1つでもFALSEがあればFALSEと出しています。
全リストに適用すると以下のようになります。
FALSEがついている行のものは判定列で「FALSE」となっていますね。
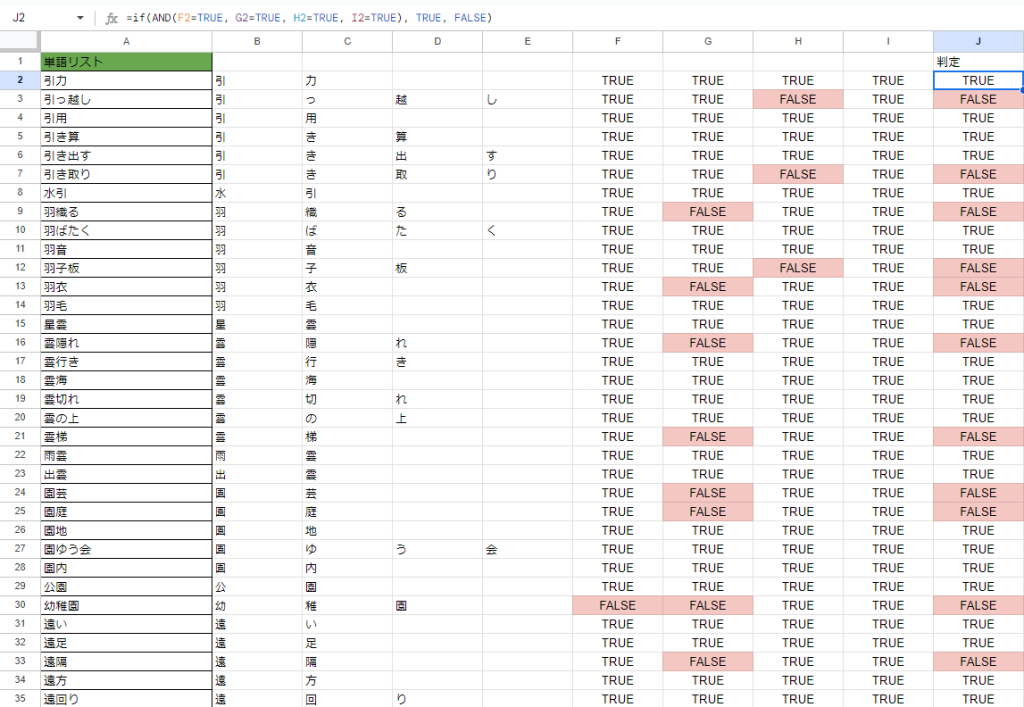
これでFALSEのものだけをリストアップしやすくなりました。あとは判定列にフィルタをかければ…
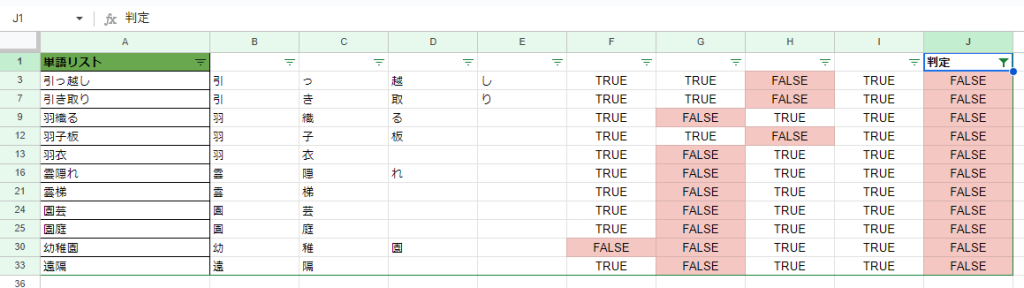
修正対象の行だけリストアップできました!
7 リストを正しく修正する
リストアップした単語を、要望通りに修正していきます。
今回の場合は「小学2年生で習っていない漢字がある」状態なので、この該当漢字をひらがなに直していきます。
たとえば一番初めの「引っ越し」。判定によると「越」の文字が対象外となっています。
元の単語リストの「引っ越し」を「引っこし」に修正すると…
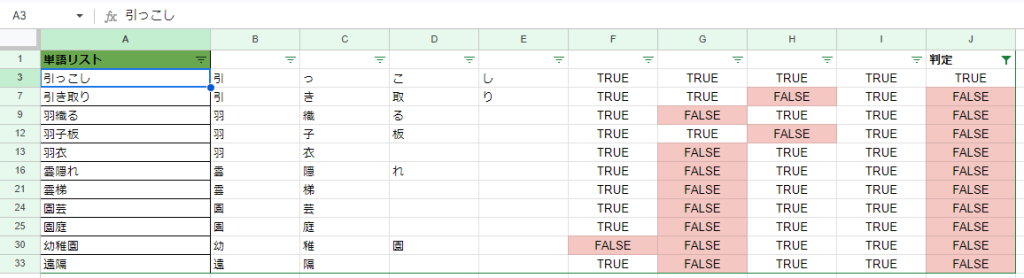
各セルの関数で再判定され、すべての結果がTRUE、利用可能な文字で構成された単語となりました。
同じようにすべての単語リストを修正していくと…
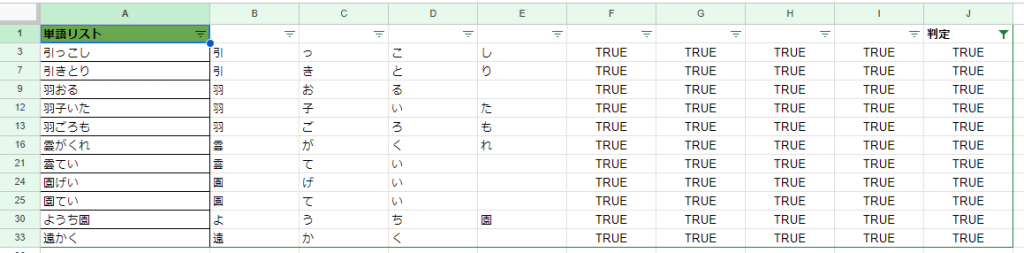
すべての結果がTRUE、真っ白のFALSEがない状態になりました。
フィルタをすべて解除してみると、FALSEがないことを確認できますよ。
これで指定の文字列を使った単語だけの作成が完了しました!
補足:プログラムで書く場合の考え方
プログラムでリスト出しをする場合も同じように、以下の流れになると思います。
- 使用可能文字列リストを作る
- 単語リストをCSVファイルなどで読み込む
- 読み込んだ単語を1文字ずつ分割して配列に入れる
- 配列をforeach等で取り出し、その文字が使用可能文字列リストにあるか判定する(PHPならin_array)
- 使用可能文字列リストにない場合、使用不可としてCSVファイル等に書き出す(または全リストを主筒力し、使用可能文字列リストにない場合は×をつけて書き出すなど)
許可できる文字列の量によって、「使用できる文字列」リストにするか「使用できない文字列」リストにするか、判断できるとスマートなプログラムになりますね。
まとめ
スプレッドシートを使って、指定外の文字列が入ったセルを探し出し、修正して確認する作業をスプレッドシート1つで行う方法を紹介しました。
この判定は自分の好きな言語のプログラムを書いてやることももちろんできます。
ですが、リストアップ後にそのままスプレッドシートで作業したい場合はスプレッドシート1つでできたほうが絶対に便利ですよ。
作業の参考になれば幸いです。


